

Fabric
Serverless compute for low-latency AI and robotics.
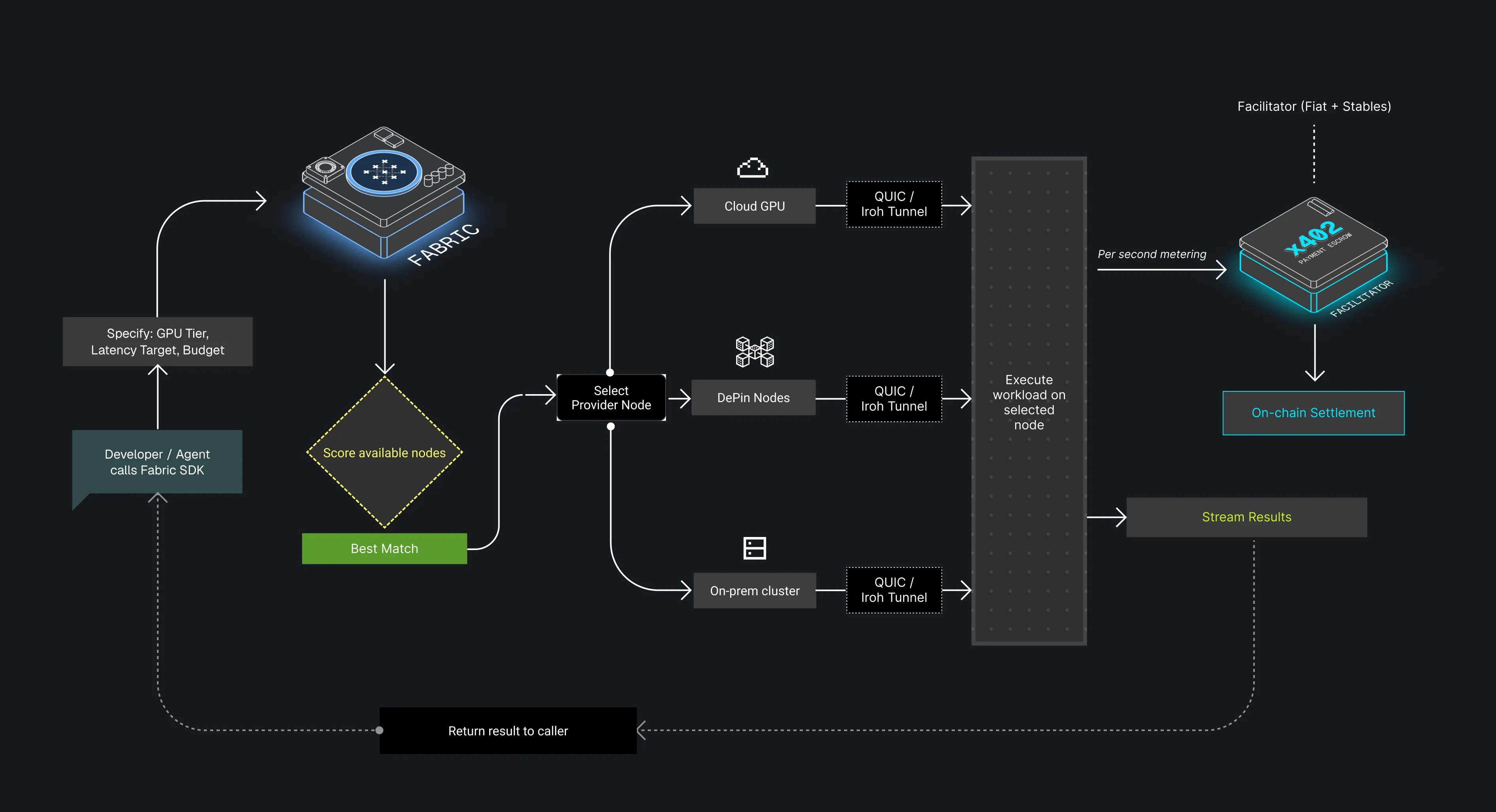
Fabric is the compute layer of CodecFlow. It pools machines from cloud providers and DePIN networks into one programmable compute mesh, accessible through an SDK, billed per second, and tuned for latency-sensitive AI work.
Think of it like Modal Labs, but built for agents, robotics, and real-time inference at the edge.
What it does
Section titled “What it does”- Orchestrates compute across providers: Fabric can route work across cloud providers such as AWS and GCP, as well as DePIN networks. Users get the best available machine without managing each provider directly.
- Schedules jobs by availability, latency, and cost: jobs are placed based on what the workload needs and what machines are available.
- Connects machines over QUIC and Iroh: nodes can talk with low latency instead of relying on slow request paths or brittle networking.
- Supports local and on-prem hardware: teams can connect their own machines to Fabric instead of using only rented cloud machines.
- Works for agents: an AI agent can request compute, receive a GPU, and pay through x402-compatible flows without a manual billing setup.
Why QUIC and Iroh matter
Section titled “Why QUIC and Iroh matter”Fabric machines communicate over QUIC through Iroh. That keeps delay low enough to split jobs across machines in ways that are not practical with plain HTTP.
A GPU model does not have to be bundled inside the same container as its worker. The model can live as its own service and be called remotely with latency low enough to feel local. GPU resources can then be shared across jobs instead of being locked to one deployment.
Python and TypeScript SDKs let developers write Fabric apps in the same style as Modal: decorate a function, set compute requirements, and deploy.
from fabric import service, GPU
@service(gpu=GPU.A100)def run_inference(frames): return model.predict(frames)The same code can run locally during development and on Fabric for production.
Payments
Section titled “Payments”Fabric is billed per second. Users pay for the machine while the workload runs, without idle charges or manual provisioning.
Agents can request and pay for machines the same way. Facilitator handles escrow for long-running sessions: funds hold upfront, draw down as compute runs, and the remainder returns when the session ends.
Who uses it
Section titled “Who uses it”- SimArena: sends heavier cloud simulation jobs to Fabric when browser physics is not enough, including Isaac Sim, Genesis, and Newton workloads.
- optr: deploys graph nodes to Fabric for production distributed jobs through graph.deploy().
- Autonomous agents: request and pay for compute on demand with x402-compatible payment flows.
Comparable products
Section titled “Comparable products”Modal Labs is the closest mental model. Fabric adds agent-native payments, DePIN provider integration, and the QUIC/Iroh mesh that supports optr streaming runtime.